Various Sorting Records.
Databrick
What is Spark ?
Apache Spark™ is a fast cluster computing framework and general engine for large-scale data processing.Spark Goals:
Generality : Diverse workloads, operators, jobsizes.
Latency:Low Latency
Fault Tolerance
Spark supports Hadoop, Amazon S3, Cassandra, cluster management tools like YARN and Mesos. Spark does more In memory data processing as compared to DiskBased processing as in Hadoop.
Spark stack comes bundled with tools like Spark SQL, MLlib, Spark Streaming and GraphX.
- SparkSQL: Unified access to structured data , provides compatibility with Apace Hive and Standard Connectivity to tools like JDBC and ODBC.
- Spark Streaming: For Scalable fault tolerant Streaming applications and spark can run in both batch and interactive mode.
- MLlib:Scalable Machine Learning library.
- GraphX:Large Scale Graph Processing Framework.

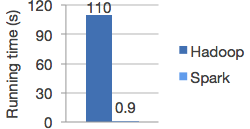
Spark vs Hadoop
Spark is 100X times faster then Hadoop.
The speed can be attributed to the fact that Spark keeps the intermediate data cached in local JVM. Hadoop on the other hand in the name of Fault Tolerance write the intermediate data on to the disk and disk is expensive.
*Image from Spark
Spark doesnt replace anything in Hadoop Ecosystem rather it offers a readable, testable way to write programs freeing us from the painful Map Reduce jobs. MR model is unsuitable for Iterative algorithms. MR jobs are pain to program too. Although there are tools to reduce our efforts in writing MR jobs like Hive, Cascading etc but internally they call MR jobs thus not improving the performance.
Spark programming model
The main abstraction for computation in Spark is Resilient(Can start automatically) Distributed Datasets.
What is RDD ?
RDD(Spark Paper) :
RDD's are fault-tolerant, parallel data structures that let users explicitly persist intermediate results in memory, control their partitioning to optimize data placement, and manipulate them using a rich set of operators.
Spark transformations applies same data operation to many data items. This results in better Fault tolerance as only the lineage of transformation is logged rather then the actual data. Also if some of RDD's are lost it has enough information to how it is derived from other RDD's.
RDD can be created through Transformations(map,filter,join). Spark creates Direct Acyclic Graph of these transformation . Once the RDD's are defined through transformations , actions can be applied on them.
Actions are application that returns a value(count,collect and save). In Spark RDD's can be stored in disk by calling persist.
Since it is just an RDD it can be queried via SQL Interface, ML algos etc.

In short
User Program =>
Create Spark Context
sc = new SparkContest
Create Distributed Datasets called RDD's
Perform Operations.
Inside spark context act as client and master per application.
Block tracker => What is in memory what is on Disk ?
Shuffle => Shuffle operation like Groupby
Scheduler talk through cluster manager talks to a worker.
Contains Block Manager for Block Mgmt.
Recieves task that run in thread pools.
Task can talk to HDFS.
No comments:
Post a Comment